背景描述
AOS8支持Cluster架构,Cluster自身存在冗余备份机制,在开启redundancy时,AP和用户都会同时和Cluster内的主备控制器之间建立隧道,当一台控制器宕机时,可以实现AP及用户的无故障切换。
用户为了达到更高的冗余性,有时会要求实现Cluster的主备,例如:用户在两个不同的数据中心分别各部署一个Cluster,要求实现当一个数据中心的整个Cluster宕机时(例如数据中心断电),可以切换到位于另一数据中心的Cluster。
解决方案
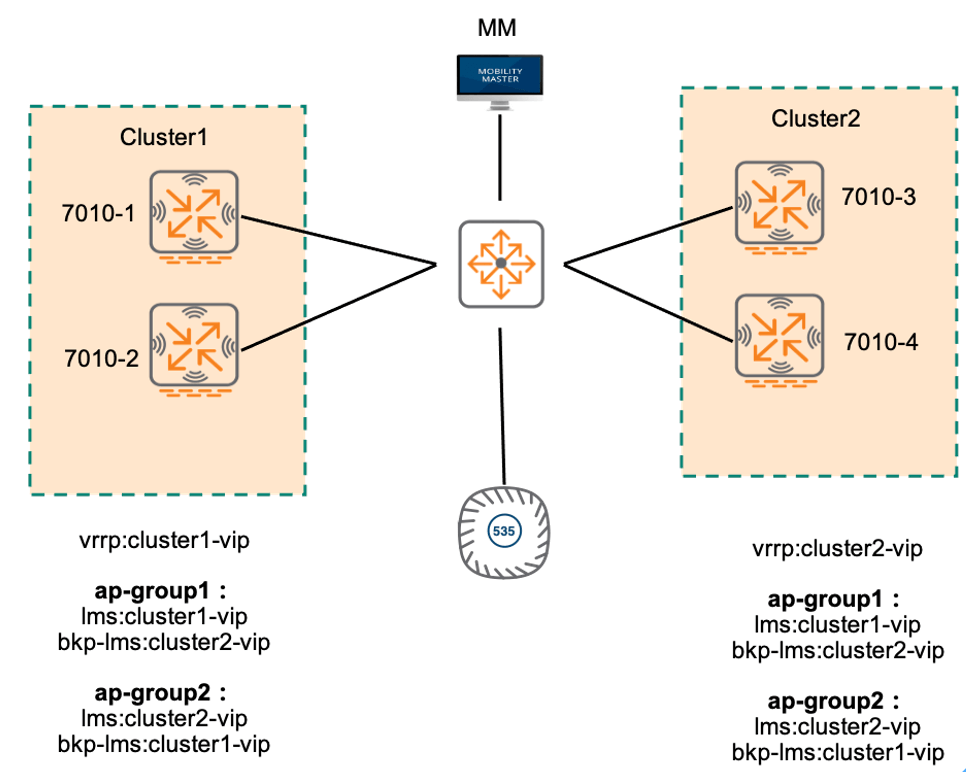
通过ap system profile中的LMS IP和Backup LMS IP设置主备Cluster,实现主备Cluster的切换,但是需要注意配置:
主备Cluster上相同AP Group的lms和bkp-lms配置应该一致。
例如:上图所示的ap-group1的主用cluster为cluster1,备用cluster为cluster2,主备cluster的ap-group1的lms均应配置为cluster1-vip,bkp-lms均应配置为cluster2-vip;
如果上图所示的cluster2不仅仅是作为备份cluster使用,同时还需要作为主cluster接管AP,那cluster2上接管的AP不能在ap-group1,只能单独再配置个AP Group,例如上图所示的ap-group2,主用cluster为cluster2,备用cluster为cluster1,主备cluster的ap-group2的lms均应配置为cluster2-vip,bkp-lms均应配置为cluster1-vip。
原因
以ap-group1中的AP为例,当cluster1 down后,AP会切换到bkp-lms(切换顺序为nodelist->cfg-blms),即切换到cluster2。此时AP认为自己连接的是bklms。当AP连接到cluster2后,会重新下载ap-group1的配置,下载的配置是lms=cluster1-vip, bklms=cluster2-vip。
当cluster1恢复,cluster2 down后,AP认为自己连接的bklms down了,需要切回lms。这时查配置,当前的lms是cluster1-vip,所以就重新连接回cluster1了。如果cluster2上ap-group1配置lms=cluster2-vip,bklms=cluster1-vip,cluster2 down后,AP要切回lms,查看配置lms=cluster2-vip,所以尝试跟cluster2-vip连接,导致连接不成功,直到PAPI失败,才会rebootstrap到cluster1,大概需要5分钟才能成功切回cluster1,而正常配置下,大概30秒即可成功切回cluster1。
两台控制器配置为集群方式 ,那么控制器和CPMM对接的IP 是哪个 ? 是物理接口IP ,还是VRRP 的虚拟IP ,或者说是集群的IP ?
两台控制器配置为VRRP 主备方式,那么和CPMM对接的是那个IP ?